Dynamic Table
Hologres推出了声明式数据处理架构Dynamic Table,该架构可以自动处理并存储一个或者多个基表(Base Table)对象的数据聚合结果,内置不同的数据刷新策略,业务可以根据需求设置不同的数据刷新策略,实现数据从基表对象到Dynamic Table的自动流转,满足业务统一开发、数据自动流转、处理时效性等诉求。
背景信息
在实时数仓场景中,通常会涉及到复杂的业务处理,例如多表关联查询、大表聚合查询等,针对不同场景,业务在时效性方面也有不同的需求:
风控、推荐等纯实时场景(实时场景):需要秒级/毫秒级出结果。
实时报表、BI看数等场景(近实时场景):时效性可以允许分钟级延迟。
定期报表、查历史数据等场景(离线场景):查询频率较低,时效性可以允许小时级延迟。
同时业务之间也会有关联查询的诉求,需要严格保证数据口径一致性。
为了满足业务资源成本、开发效率及业务时效性等需求,业界做了比较多的架构研究演进,例如早期的Lambda架构、流批一体架构等,虽然解决了部分业务/开发问题,但还存在以下问题:
架构上:目前市面上的产品通过相互组合的解决方案,来支持不同业务场景不同时效性的业务诉求。不能在一个产品里满足所有业务诉求。
数据加工上(ETL):从明细层到应用层,实时数仓没有明确的方法论,无法做到更低成本的数据自动流动,资源成本高、开发效率低。
基于上述背景,Hologres重磅推出Dynamic Table,支持全量、增量的数据处理模式,实现更高效、更低成本的数据自动流动与分层。通过Dynamic Table,结合Hologres本身特性,能够统一存储层、统一计算层、统一数据服务层,满足开发效率、时效性等需求。
Dynamic Table的优势
简化数仓架构
Dynamic Table多种刷新模式可实现不同级别的时延,满足业务不同时效性的查询诉求,再基于Hologres的统一存储(存储实时数据、离线数据),直接赋能业务OLAP查询、在线服务、AI与大模型等多个应用场景的查询诉求,有效简化数仓架构,节约开发、运维成本。
自动数仓分层
Dynamic Table可以自动刷新数据,实现数据从ODS>DWD>DWS>ADS的自动数据流转,提升数仓分层体验。
提升数据处理(ETL)效率
Dynamic Table支持全量刷新和增量刷新,满足业务的不同时效性处理需求。对于增量刷新,只处理增量数据,减少ETL计算数据量,显著提升数据处理效率。
简化开发维护
Dynamic Table自动管理刷新任务,以及数据之间的层级和依赖关系,简化繁琐的开发运维流程,提升开发效率。

基本概念
基表(Base Table)
Dynamic Table中数据来源的基表,可以是一张表(内部表或外部表),也可以是多个表关联。不同的刷新模式,支持的基表类型不同。详情请参见Dynamic Table支持范围和限制。
Query
创建Dynamic Table时指定的Query,是指对基表数据的处理Query,相当于ETL过程。不同的刷新模式支持的Query类型不同,详情请参见Dynamic Table支持范围和限制。
刷新(Refresh)
当基表中的数据发生变化时,需要通过刷新(Refresh)Dynamic Table以更新数据的变动。Dynamic Table会根据设置的刷新开始时间和刷新间隔,自动在后台运行刷新任务,对刷新任务的观测和运维详情请参见运维Dynamic Table刷新任务。
技术原理
基表中的数据根据Dynamic Table中Query定义的数据处理流程,通过刷新的方式写入Dynamic Table。以下将从刷新模式、计算资源、数据存储及表索引四个方面介绍Dynamic Table的部分技术原理。
刷新模式
当前Dynamic Table支持两种刷新模式,即全量刷新(Full)和增量刷新(Incremental),根据设置的刷新模式不同,Dynamic Table的技术原理也有所差异。
全量刷新(Full)
全量刷新是指每次执行刷新时,都以全量的方式进行数据处理,并将基表的聚合结果物化写入Dynamic Table,其技术原理类似于INSERT OVERWRITE的相关原理。
增量刷新(Incremental)
增量刷新模式下,每次刷新时只会读取基表中新增的数据,根据中间聚合状态和增量数据计算最终结果并更新到Dynamic Table中。相比全量刷新,增量刷新每次处理的数据量更少,效率更高,从而可以非常有效地提升刷新任务的时效性,同时降低计算资源的使用。
技术原理
创建了增量刷新的Dynamic Table后,系统会在底层创建一个列存的状态表(State表),用于存储Query的中间聚合状态,引擎在编码、存储等方面对中间聚合状态进行了优化,可以加快对中间聚合状态的读取和更新。增量数据会以微批次方式做内存态的聚合,再与状态表中的数据进行合并,然后以BulkLoad的方式将最新聚合结果高效地写入Dynamic Table。微批次的增量处理方式减少了单次刷新的数据处理量,显著提升了计算的时效性。
注意事项
增量刷新模式支持的基表存在一定的限制,详情请参见Dynamic Table支持范围和限制。
增量刷新需要基表开启Binlog,以此感知基表的数据变化,详情请参见订阅Hologres Binlog。
增量刷新内置的状态表会占用一定的存储,系统会设置TTL定期清理数据,您可以使用函数查看状态表的存储大小,详情请参见状态表(State)管理。
计算资源
执行刷新任务的计算资源可以是本实例的资源或者Serverless资源:
本实例资源:刷新任务将会使用本实例的资源运行,与实例中的其他任务共享资源,高峰期可能会出现资源争抢现象。
Serverless资源(默认):默认会将刷新任务通过Serverless方式执行,如果Query比较复杂,处理的数据量较多,通过Serverless方式可以有效地提升刷新任务的稳定性,避免本实例内多任务间的资源争抢,同时也可以对单个刷新任务修改计算资源,以便更合理地使用Serverless资源。
数据存储
Dynamic Table在数据存储方面与普通表一致,默认使用热存储模式。为了减少存储成本,也可以将查询频率较低的数据设置为冷存储,有效降低成本。
表索引
业务在查询时,可以直接查询Dynamic Table,相当于直接查询聚合结果,这样可以显著提升查询性能。同时,Dynamic Table也如同普通表,支持设置表索引,如行存/列存、Distribution Key、Clustering Key等,通常情况下,引擎会根据Dynamic Table的Query推导出合适的索引,如业务有进一步的调优需求,可以重新为其设置合适的索引,以进一步提升查询性能。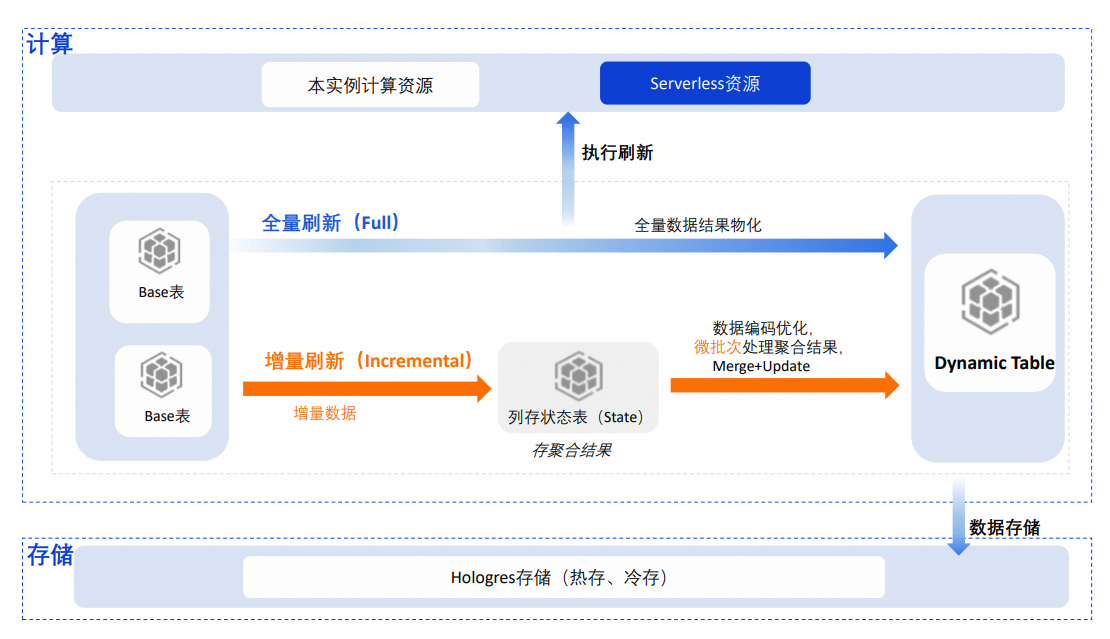
与物化视图对比
Dynamic Table VS Hologres实时物化视图
Hologres在V1.3版本推出了SQL管理物化视图,但是支持的能力相对较弱,与Dynamic Table的差异如下:
功能分类 | Hologres Dynamic Table | Hologres实时物化视图 |
基表类型 |
| 单内表 |
基表操作 |
| 仅支持append写入 |
刷新原理 | 异步刷新(全量刷新、增量刷新) | 同步刷新 |
刷新时效性 |
| 实时 |
Query类型 |
说明 不同的刷新模式,支持的Query类型不同,详情请参见Dynamic Table支持范围和限制。 | 有限算子支持(AGG、RB函数等) |
查询模式 | 直接查Dynamic Table |
|
Dynamic Table VS 异步物化视图
当前市面上,与Dynamic Table功能类似的有OLAP产品的异步物化视图、Snowflake的Dynamic Table等,其差别如下:
功能分类 | Hologres Dynamic Table | OLAP产品异步物化视图 | Snowflake Dynamic Table |
基表类型 |
说明 不同的刷新模式,支持的Query类型不同,详情请参见Dynamic Table支持范围和限制。 |
|
|
刷新模式 |
|
|
|
刷新时效性 |
| 小时级 |
|
Query类型 |
说明 不同的刷新模式,支持的Query类型不同,详情请参见Dynamic Table支持范围和限制。 |
|
|
查询模式 | 直接查Dynamic Table |
| 直接查Dynamic Table |
观测/运维 |
| 丰富的监控指标 | 可视化界面 |
使用场景
Dynamic Table可以自动完成数据加工和存储,通过Dynamic Table,可以加速数据查询,提升业务时效性,推荐您在湖仓加速和数仓分层场景中使用。
湖仓加速
Dynamic Table的基表数据可以来源于Hologres表,也可以来源于数据仓库,例如MaxCompute、数据湖OSS、Paimon等,通过对基表数据的全量/增量刷新,满足不同时效性的数据查询探索需求。推荐的使用场景包括:
定期报表查询
对于周期性观测的相关场景,例如周期性报表等,如果数据量较少或者Query不复杂,可以使用全量刷新或者增量刷新的模式,周期性地将湖仓数据的聚合分析结果刷新至Dynamic Table,应用侧直接查询Dynamic Table获取分析结果,加速报表查询。
实时大屏/报表
对于实时大屏和实时报表等场景,数据的时效性要求更高,推荐使用增量刷新的模式,将湖Paimon或者实时数据的聚合分析结果刷新至Dynamic Table,以此来加速对实时数据的处理,应用侧直接查询Dynamic Table获取数据分析结果,达到近实时分析的目的。

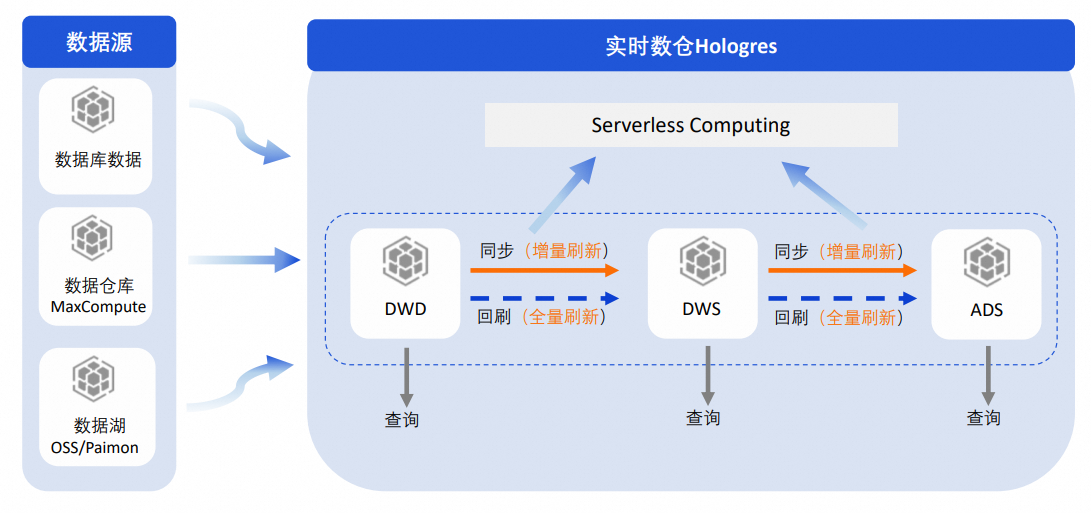
数仓分层
如果基表中有大量数据,需要进行复杂的ETL处理来满足业务的时效性需求,常见的做法就是数仓分层。对于实时数仓,业界在数仓分层上的方案较多,例如使用物化视图、周期性调度等,这些方案虽然能解决一部分问题,但也都存在数据时效性、开发不便捷等问题。而Hologres Dynamic Table本身就具备数据自动处理的能力,因此可以通过Dynamic Table方便地实现数仓分层。
推荐做法如下:
可以在Hologres中通过Dynamic Table构建数仓分层DWD>DWS>ADS:
每一层之间的数据同步使用增量刷新模式,这样可以确保每一层处理的数据量更少,减少不必要的重复计算,提升同步速度。也可以根据业务情况,将刷新任务提交到Serverless Computing执行,进一步提升刷新的时效性和稳定性。
如果要对每一层的数据进行回刷,可以使用全量刷新模式执行一次刷新,以此来保证每一层数据口径的一致性。同样也可以根据业务情况,将刷新任务提交到Serverless Computing执行,进一步提升刷新的时效性和稳定性。
每一层都在Hologres中构建,数仓分层明确,每一层都可以根据业务情况提供查询,保证数据的可见性、复用性。
通过Hologres Dynamic Table方案即可完成数据加工+应用的场景,显著提升数仓开发、运维效率。